
Using APIs for Data Imports #
This chapter starts by using the FRED API with the package fredapi. We’ll also see our first set of simulations. I’ll then show you how to use Pandas Data Reader.
This is also our first time using an API. Their API, or Application Programming Interface, lets us talk to a remote data storage system and pull in what we need. APIs are more general, though, and are used whenever you need one application to talk to another.
We can again use pip to install packages via the command line or in your Jupyter notebook. You can type this directly into a code cell in a notebook in Github Codespaces. Run that cell.
!pip install fredapi
Once you’ve installed a package in a Codespace, you don’t need to run that code again. You can comment it out so that you don’t load it every time you run the notebook.
When you sign-up for the FRED API, you’ll get an API Key. You will need to add this key to the set-up to access either service.
For security, never hardcode your API key in your script. Instead, store it in an environment variable and retrieve it using the methods described below. When working in Github Codespaces, you can store your API key in a secret. This keeps your API key hidden and prevents accidental exposure in shared code.
You can also install `pandas-datareader` using `pip`. This API has additional data that you can bring in.
!pip install pandas-datareader
Finally, for a large set of APIs for access data, check out [Rapid API](https://rapidapi.com/hub). Some are free, others you have to pay for. You'll need to get an access API key for each one. More on this at the end of these notes.
FRED Example#
Let’s do our usual sort of set-up code.
# Set-up
from fredapi import Fred
import nasdaqdatalink # You could also do something like: import nasdaqdatalink as ndl
import pandas_datareader as pdr
import os
from dotenv import load_dotenv
import numpy as np
import pandas as pd
import datetime as dt
import matplotlib as mpl
import matplotlib.pyplot as plt
# Include this to have plots show up in your Jupyter notebook.
%matplotlib inline
/opt/anaconda3/lib/python3.9/site-packages/pandas/core/computation/expressions.py:21: UserWarning: Pandas requires version '2.8.4' or newer of 'numexpr' (version '2.8.3' currently installed).
from pandas.core.computation.check import NUMEXPR_INSTALLED
/opt/anaconda3/lib/python3.9/site-packages/pandas/core/arrays/masked.py:60: UserWarning: Pandas requires version '1.3.6' or newer of 'bottleneck' (version '1.3.5' currently installed).
from pandas.core import (
# Load API keys from .env file
load_dotenv()
# Retrieve API keys
FRED_API_KEY = os.getenv('FRED_API_KEY')
# Initialize FRED API
fred = Fred(api_key=FRED_API_KEY)
In order for you to use fredapi, you’ll need to set up a FRED account. You can then request and find your API key here.
Here’s one way. The not-very-safe way. Copy and paste that key into:
# ❌ Insecure way (Don't do this!)
fred = Fred(api_key='your_api_key_here')
That will work. But, copying and pasting your API keys like this is, in general, a very bad idea! After all, if someone has you API key, they can charge things to your account. Github and Codespaces has a way around this, though.
Let’s use Github Secrets to create an environment variable that you can associate with any of your repositories. Then, within a repo, you can access that “secret” variable, without actually typing it into your code.
Go to your main Github page at Github.com. Click on your image in the upper-right. Go to Settings. Click on Codespaces under Code, planning, and automation.
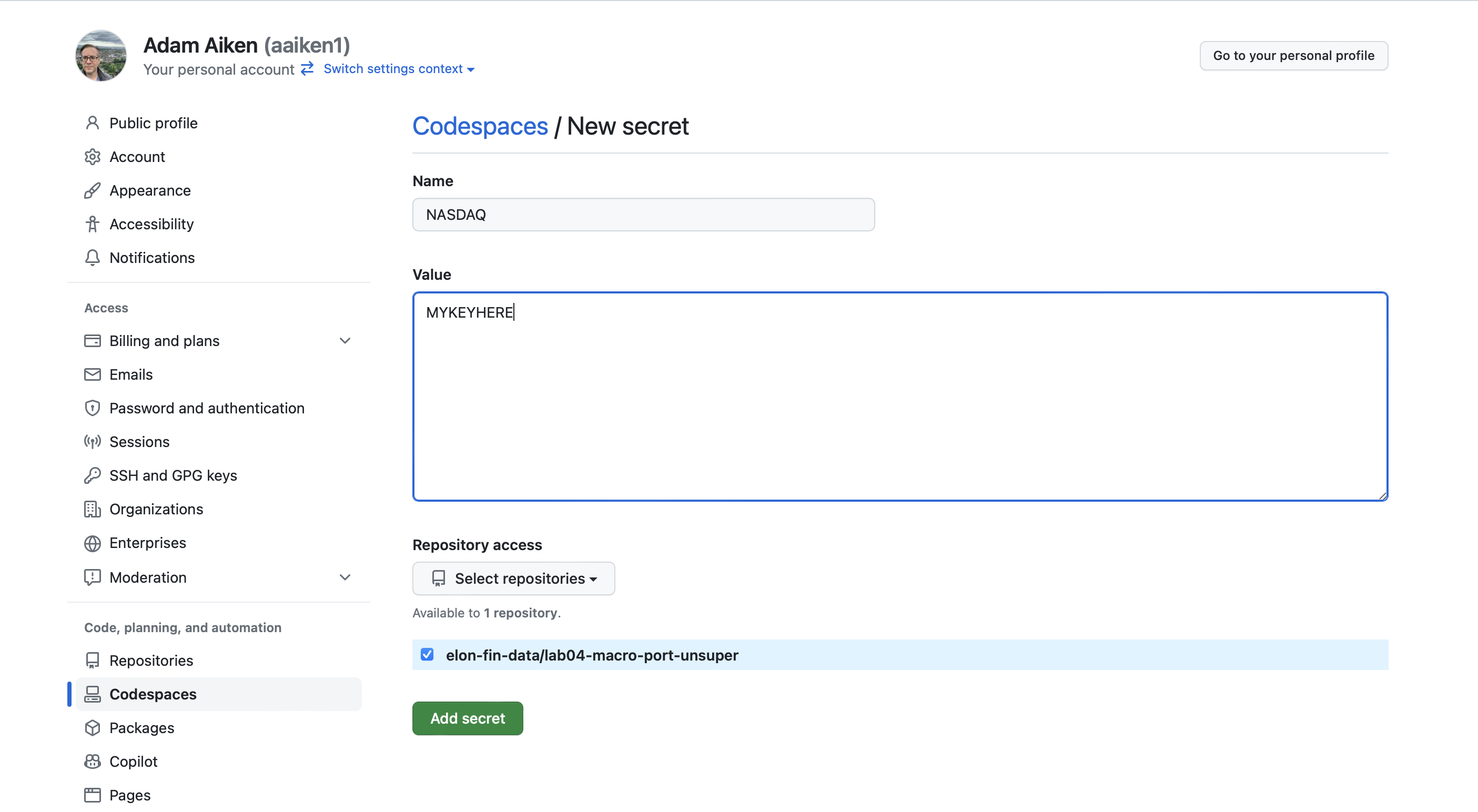
Click on New Secret under Codespaces Secrets. You can now name your secret (e.g. NASDAQ) and copy your API key in the box below. Select the repo(s) that you want to associate with this secret. Click the green Add Secret.
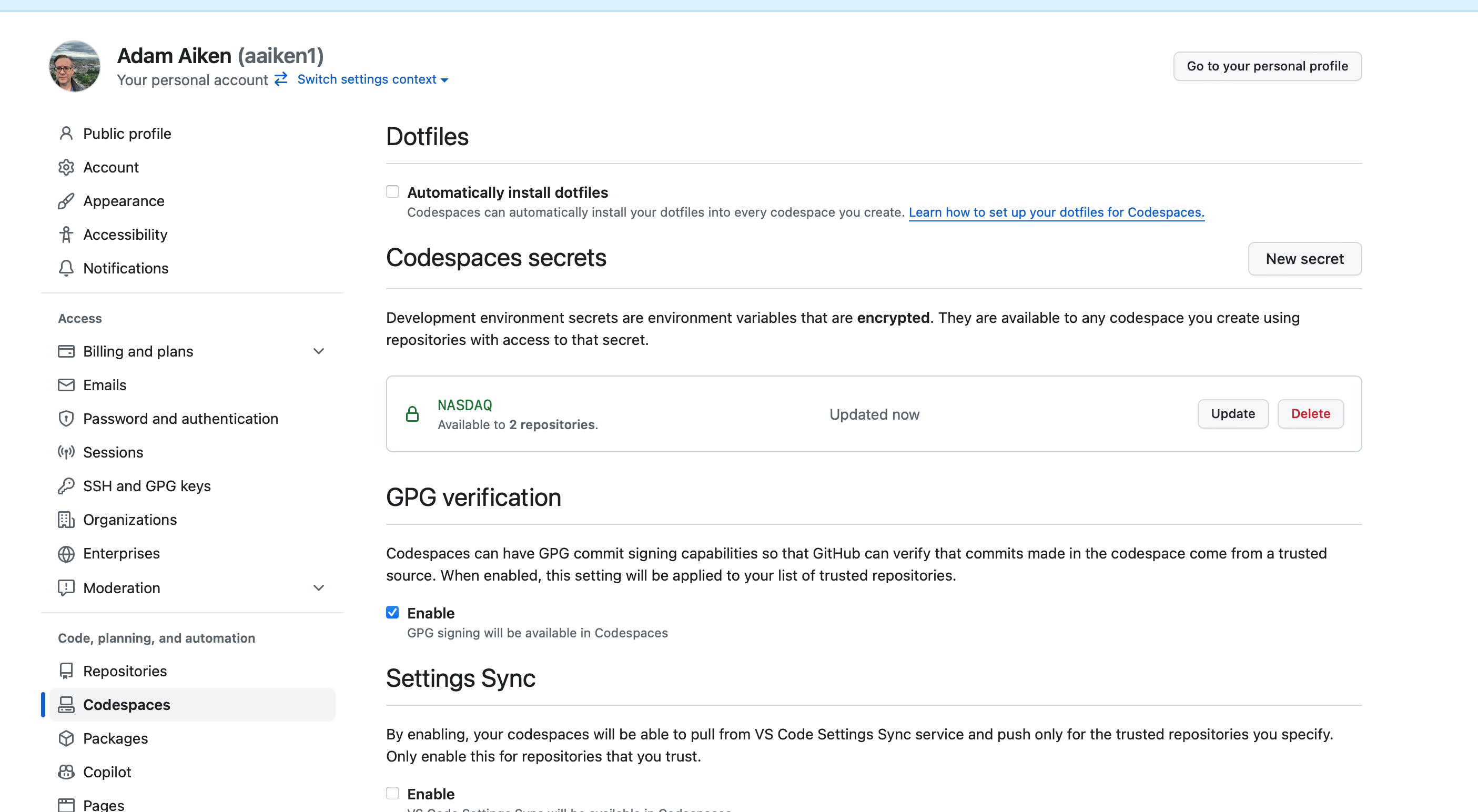
You’ll now see that secret in the main Codespace settings page. You can refer to the name of that secret in your Codespace now, like I do below. Note that you need to import the os package to access this environment variable. An environment variable is a variable defined for all of the work in this particular repo. My secret is named NASDAQ, so I can refer to that.
If you had your Codespace running in another tab before adding the secret, you’ll need to restart it:
Click on the Codespaces tab in your GitHub repository.
Select your active Codespace.
Click Stop Codespace and then Restart it. This refreshes your environment, allowing the secret to be accessed.
This is the code for accessing your FRED secret, which contains the API key.
# ✅ Secure way (Recommended)
from fredapi import Fred
import os
# My Secret for this Repo is called FRED
FRED_API_KEY = os.environ.get('FRED')
# Here, I'm setting the API key so that I can access the FRED server
fred = Fred(api_key=FRED_API_KEY)
With my API key read, I can now start downloading data.
Just for fun, let’s start with Bitcoin data. You can see the FRED page for it here. Search around on FRED for the data you would like and then note the code for it. That code is how I can access it via the API.
btc = fred.get_series('CBBTCUSD')
btc.tail()
2026-01-14 96852.91
2026-01-15 95569.99
2026-01-16 95467.76
2026-01-17 95015.57
2026-01-18 92624.74
dtype: float64
That’s just a plain series, not a DataFrame. Let’s turn it into a DataFrame, create an index, and add column names.
btc = btc.to_frame(name='btc')
btc = btc.rename_axis('date')
btc
| btc | |
|---|---|
| date | |
| 2014-12-01 | 370.00 |
| 2014-12-02 | 378.00 |
| 2014-12-03 | 378.00 |
| 2014-12-04 | 377.10 |
| 2014-12-05 | NaN |
| ... | ... |
| 2026-01-14 | 96852.91 |
| 2026-01-15 | 95569.99 |
| 2026-01-16 | 95467.76 |
| 2026-01-17 | 95015.57 |
| 2026-01-18 | 92624.74 |
4067 rows × 1 columns
There are some missing values early on in the data. I’m not going to explore it too much - let’s just drop them. Bitcoin in 2015? That’s ancient history!
btc = btc.dropna()
btc['ret'] = btc.pct_change().dropna()
/var/folders/kx/y8vj3n6n5kq_d74vj24jsnh40000gn/T/ipykernel_81749/623421051.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
btc['ret'] = btc.pct_change().dropna()
btc = btc.loc['2015-01-01':,['btc', 'ret']]
btc.plot()
<AxesSubplot:xlabel='date'>
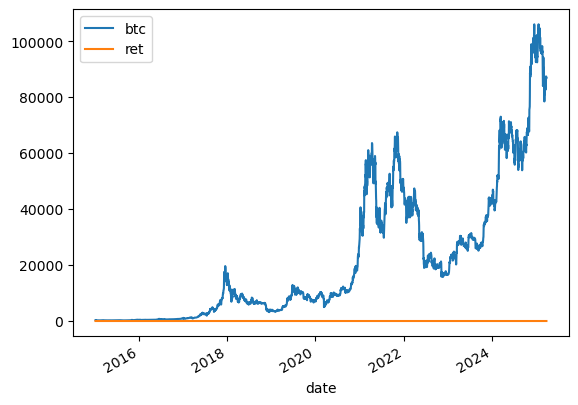
Well, that’s not a very good graph. The returns and price levels are in different units. Let’s use an f print to show and format the average BTC return.
print(f'Average return: {100 * btc.ret.mean():.2f}%')
Average return: 0.21%
Let’s make a cumulative return chart and daily return chart. We can then stack these on top of each other. I’ll use the .sub(1) method to subtract 1 from the cumulative product. You see this a lot in the DataCamps.
btc['ret_g'] = btc.ret.add(1) # gross return
btc['ret_c'] = btc.ret_g.cumprod().sub(1) # cummulative return
btc
| btc | ret | ret_g | ret_c | |
|---|---|---|---|---|
| date | ||||
| 2015-01-08 | 288.99 | -0.150029 | 0.849971 | -0.150029 |
| 2015-01-13 | 260.00 | -0.100315 | 0.899685 | -0.235294 |
| 2015-01-14 | 120.00 | -0.538462 | 0.461538 | -0.647059 |
| 2015-01-15 | 204.22 | 0.701833 | 1.701833 | -0.399353 |
| 2015-01-16 | 199.46 | -0.023308 | 0.976692 | -0.413353 |
| ... | ... | ... | ... | ... |
| 2026-01-14 | 96852.91 | 0.017120 | 1.017120 | 283.861500 |
| 2026-01-15 | 95569.99 | -0.013246 | 0.986754 | 280.088206 |
| 2026-01-16 | 95467.76 | -0.001070 | 0.998930 | 279.787529 |
| 2026-01-17 | 95015.57 | -0.004737 | 0.995263 | 278.457559 |
| 2026-01-18 | 92624.74 | -0.025163 | 0.974837 | 271.425706 |
4023 rows × 4 columns
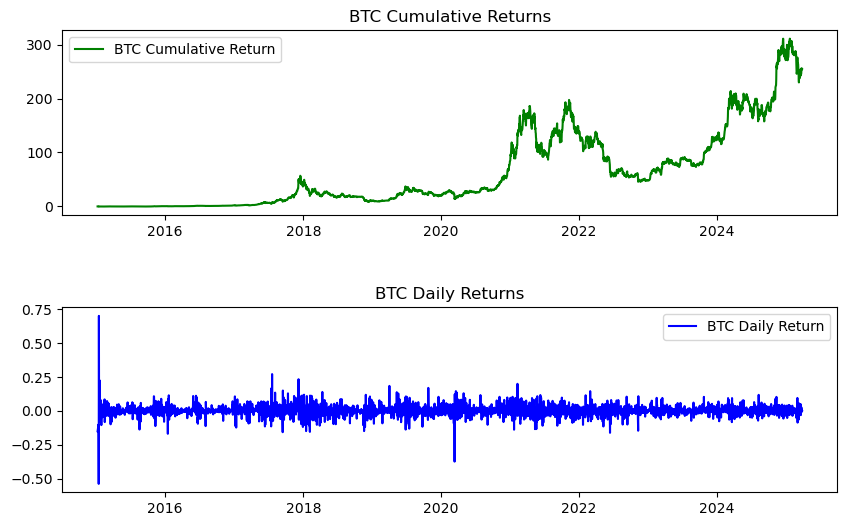
We can now make a graph using the fig, axs method. This is good review! Again, notice that semi-colon at the end. This suppresses some annoying output in the Jupyter notebook.
fig, axs = plt.subplots(2, 1, sharex=True, sharey=False, figsize=(10, 6))
axs[0].plot(btc.ret_c, 'g', label = 'BTC Cumulative Return')
axs[1].plot(btc.ret, 'b', label = 'BTC Daily Return')
axs[0].set_title('BTC Cumulative Returns')
axs[1].set_title('BTC Daily Returns')
axs[0].legend()
axs[1].legend();
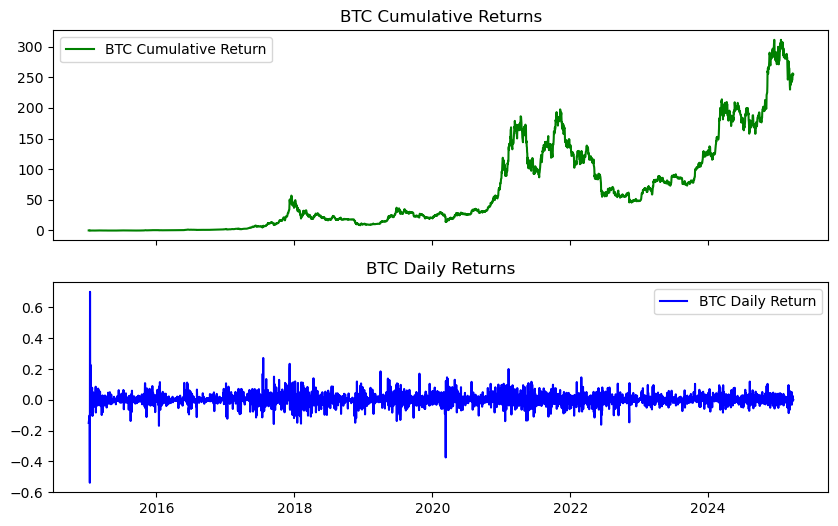
I can make the same graph using the .add_subplot() syntax. The method above gives you some more flexibility, since you can give both plots the same x-axis.
fig = plt.figure(figsize=(10, 6))
ax1 = fig.add_subplot(2, 1, 1)
ax1.plot(btc.ret_c, 'g', label = 'BTC Cumulative Return')
ax2 = fig.add_subplot(2, 1, 2)
ax2.plot(btc.ret, 'b', label = 'BTC Daily Return')
ax1.set_title('BTC Cumulative Returns')
ax2.set_title('BTC Daily Returns')
ax1.legend()
ax2.legend()
plt.subplots_adjust(wspace=0.5, hspace=0.5);
A BTC Simulation#
Let’s put together some ideas, write a function, and run a simulation. We’ll use something called geometric brownian motion (GBM). What is GBM? It is a particular stochastic differential equation. But, what’s important for us is the idea, which is fairly simple. Here’s the formula:
This says that the change in the stock price has two components - a drift, or average increase over time, and a shock that it is random at each point in time. The shock is scaled by the standard deviation of returns that you use. So, larger standard deviation, the bigger the shocks can be. This is basically the simplest way that you can model an asset price.
The shocks are what make the price wiggle around around, or else it would just go up over time, based on the drift value that we use.
And, I’ll stress - we aren’t predicting here, so to speak. We are trying to capture some basic reality about how an asset moves and then seeing what is possible in the future. We aren’t making a statement about whether we think an asset is overvalued or undervalued, will go up or down, etc.
You can solve this equation to get the value of the asset at any point in time t. You just need to know the total of all of the shocks at time t.
T = 30 # How long is our simulation? Let's do 31 days (0 to 30 the way Python counts)
N = 30 # number of time points in the prediction time horizon, making this the same as T means that we will simulate daily returns
S_0 = btc.btc[-1] # initial BTC price
N_SIM = 100 # How many simulations to run?
mu = btc.ret.mean()
sigma = btc.ret.std()
/var/folders/kx/y8vj3n6n5kq_d74vj24jsnh40000gn/T/ipykernel_81749/160269624.py:3: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
S_0 = btc.btc[-1] # initial BTC price
This is the basic syntax for writing a function in Python. We saw this earlier, back when doing “Comp 101”. Remember, in Python, indentation matters!
def simulate_gbm(s_0, mu, sigma, n_sims, T, N):
dt = T/N # One day
dW = np.random.normal(scale = np.sqrt(dt),
size=(n_sims, N)) # The random part
W = np.cumsum(dW, axis=1)
time_step = np.linspace(dt, T, N)
time_steps = np.broadcast_to(time_step, (n_sims, N))
S_t = s_0 * np.exp((mu - 0.5 * sigma ** 2) * time_steps + sigma * np.sqrt(time_steps) * W)
S_t = np.insert(S_t, 0, s_0, axis=1)
return S_t
Nothing happens when we define a function. We’ve just created something called simulate_gbm that we can now use just like any other Python function.
We can look at each piece of the function code, with some numbers hard-coded, to get a sense of what’s going on. This gets tricky - keep track of the dimensions. I think that’s the hardest part. How many numbers are we creating in each array? What do they mean?
# Creates 100 rows of 30 random numbers from the standard normal distribution.
dW = np.random.normal(scale = np.sqrt(1),
size=(100, 30))
# cumulative sum along each row
W = np.cumsum(dW, axis=1)
# Array with numbers from 1 to 30
time_step = np.linspace(1, 30, 30)
# Expands that to be 100 rows of numbers from 1 to 30. This is going to be the t in the formula above. So, for the price on the 30th day, we have t=30.
time_steps = np.broadcast_to(time_step, (100, 30))
# This is the formula from above to find the value of the asset any any point in time t. np.exp is the natural number e. W is the cumulative sum of all of our random shocks.
S_t = S_0 * np.exp((mu - 0.5 * sigma ** 2) * time_steps + sigma * np.sqrt(time_steps) * W)
# This inserts the initial price at the start of each row.
S_t = np.insert(S_t, 0, S_0, axis=1)
We can look at these individually, too.
dW
array([[ 0.25846575, 0.21439205, -0.90007245, ..., 0.93251147,
-0.92975543, -0.82352081],
[ 1.70020644, -0.71321019, -0.95538906, ..., -0.21315645,
-2.41191361, 0.38115677],
[-2.30401431, 1.05094515, -2.92488298, ..., 1.70411849,
-0.18682808, -1.01319038],
...,
[ 0.22368589, 0.27130122, 0.74510819, ..., -0.87741032,
-0.25179827, -0.03522041],
[ 0.69194317, 0.95110324, 0.47174301, ..., -0.095117 ,
0.18464386, -0.72975307],
[ 0.71681547, 0.81013739, 0.82105049, ..., -0.34280018,
0.26584576, -0.37499531]])
time_steps
array([[ 1., 2., 3., ..., 28., 29., 30.],
[ 1., 2., 3., ..., 28., 29., 30.],
[ 1., 2., 3., ..., 28., 29., 30.],
...,
[ 1., 2., 3., ..., 28., 29., 30.],
[ 1., 2., 3., ..., 28., 29., 30.],
[ 1., 2., 3., ..., 28., 29., 30.]])
len(time_steps)
100
np.shape(time_steps)
(100, 30)
I do this kind of step-by-step break down all of the time. It’s the only way I can understand what’s going on.
We can then use our function. This returns an narray.
gbm_simulations = simulate_gbm(S_0, mu, sigma, N_SIM, T, N)
And, we can plot all of the simulations. I’m going to use pandas to plot, save to ax, and the style the ax.
gbm_simulations_df = pd.DataFrame(np.transpose(gbm_simulations))
# plotting
ax = gbm_simulations_df.plot(alpha=0.2, legend=False)
ax.set_title('BTC Simulations', fontsize=16);
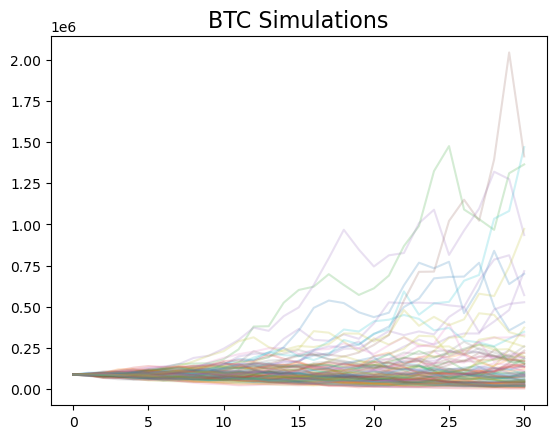
The y-axis has a very wide range, since some extreme values are possible, given this simulation.
pandas-datareader#
The pandas data-reader API lets us access additional data sources, such as FRED.
There are also API that let you access the same data. For example, Yahoo! Finance has several, like yfinance. I find accessing Yahoo! Finance via an API to be very buggy - Yahoo! actively tries to stop it. So, you can try those instructions, but they may or may not work.
Lots of developers have written APIs to access different data sources.
Note
Different data sources might require API keys. Sometimes you have to pay. Always read the documentation.
Here’s another FRED example, but using pandas-datareader.
start = dt.datetime(2010, 1, 1)
end = dt.datetime(2013, 1, 27)
gdp = pdr.DataReader('GDP', 'fred', start, end)
gdp.head()
| GDP | |
|---|---|
| DATE | |
| 2010-01-01 | 14764.610 |
| 2010-04-01 | 14980.193 |
| 2010-07-01 | 15141.607 |
| 2010-10-01 | 15309.474 |
| 2011-01-01 | 15351.448 |
NASDAQ API#
Let’s look at the NASDAQ Datalink API. You’ll need to create an account and then get the API key. You can set up an account here. Choose an Academic account. You will also be asked to set-up an authentication method. I used Google Authenticator on my phone. When you try to log in, you’ll need to go to the app and get the six-digit number.
Once you log in, you might see a My Apps dashboard. Click the icon in the middle - you’ll be able to go to this page: https://data.nasdaq.com.
That’s the main data API page. There’s a SEARCH FOR DATA box at the top.
Fig. 35 NASDAQ API homepage.#
You can go to your account profile to get your API key: https://data.nasdaq.com/account/profile. You should create a Github Secret for this key and then assign it to your repo. As a reminder, you do this by going to your Github account, clicking on your image in the upper-right, going to Settings, and then Codespaces. You can then add a new secret and aassign it to your repo. I’d call the secret NASDAQ.
Remember, you’ll need to restart your Codespace once you add a secret.
Back to the data. If you click EXPLORE next to the search box at the top of the main data page, you’re taken to a list of all of their data. Much of it is premium - you have to pay. However, you can filter for free data. There’s not much - most of the free data comes from Quandl, which was purchased by Nasdaq recently.
Quandl has been completely integrated by NASDAQ now, though you will see legacy instructions on the website that refer to its older API commands.
Fig. 36 Exploring NASDAQ data options.#
Let’s look at the Zillow data. You can find that data here.
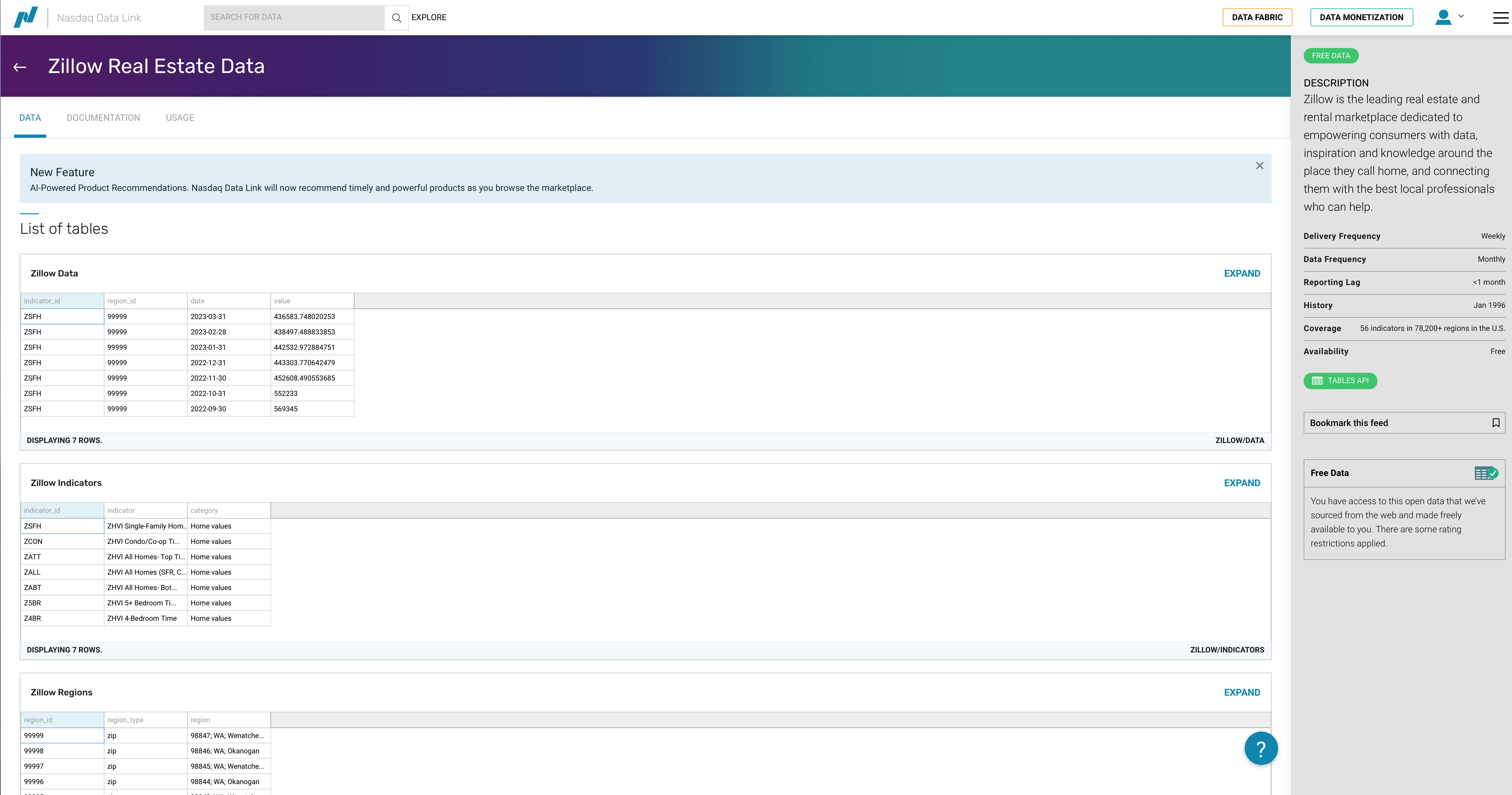
Fig. 37 NASDAQ has an API for Zillow housing data.#
Each the data APIs shows you samples of what you can access. So, we see an example table with data for a particular indicator, region, date and value. There’s a dropdown menu that lets you select one of three data sets available to see a preview.
Scrolling down, you’ll be able to read more about these three data sets and what’s in them.
The data structure makes it clear that we can download value data and then merge in ID and region descriptions if needed. But, how do we do that? See the row across the top, next to Zillow Real Estate Data? You can click on DOCUMENTATION and USAGE to learn more. We’ll look at a quick example here.
Click USAGE and then the Python icon. You can get to the same place by just scrolling down too.
You’ll seen an example that lets you filter by a single indicator_id and region. It has your API key and the .get_table method.
Make sure that you include your API key. You can input it directly, using the code that they provide, but this isn’t the preferred method. Instead, use a Github Secret, like we did above.
To use the NASDAQ API, you’ll need to install the package.
%pip install nasdaq-data-link
This code brings in the API key from my local .env file. You want to use the Github Secret method. Since my notes aren’t being compiled in a Codespace, I don’t actually do things that way here. Instead, you want to do this:
# ✅ Secure way (Recommended)
%pip install nasdaq-data-link
import nasdaqdatalink as ndl
import os
# My Secret for this Repo is called NASDAQ
NASDAQ_API_KEY = os.environ.get('NASDAQ')
# Here, I'm setting the API key so that I can access the FRED server
ndl.ApiConfig.api_key = NASDAQ_API_KEY
Note that, in this version, I’m doing import nasdaqdatalink as ndl. Just to show you that you can abbreviate the package name. You can comment out the %pip once you’ve installed the package in that Codespace.
#%pip install nasdaq-data-link
# Bring in nasdaqdatalink for downloading data. Note how you don't have the dashes in the package name.
import nasdaqdatalink
NASDAQ_API_KEY = os.getenv('NASDAQ_API_KEY')
nasdaqdatalink.ApiConfig.api_key = 'NASDAQ_API_KEY'
nasdaqdatalink.read_key()
Let’s try pulling in the indicator_id ZATT for all regions.
# zillow = nasdaqdatalink.get_table('ZILLOW/DATA', indicator_id = 'ZATT', paginate=True)
You need that paginate=True in there in order to download all of the available data. Without it, it will only pull the first 10,000 rows. Using paginate extends the limit to 1,000,000 rows, or observations. Now, note that this could be a lot of data! You might need to download the data in chunks to get what you want.
I’ve commented out the code above, because I know it will exceed the download limit! So, we need to be more selective.
If you look on the NASDAQ Zillow documentation page, you’ll see the three tables that you can download, the variables inside of each, and what you’re allowed to filter on. You unfortunately can’t filter on date in the ZILLOW/DATA table. Other data sets, like FRED, do let you specify start and end dates. Every API is different.
You can find examples of how to filter and sub-select your data on the NASDAQ website: https://docs.data.nasdaq.com/docs/python-tables
However, you can filter on region_id. Let’s pull the ZILLOW/REGIONS table to see what we can use.
regions = nasdaqdatalink.get_table('ZILLOW/REGIONS', paginate=True)
regions
| region_id | region_type | region | |
|---|---|---|---|
| None | |||
| 0 | 99999 | zip | 98847;WA;Wenatchee, WA;Leavenworth;Chelan County |
| 1 | 99998 | zip | 98846;WA;nan;Pateros;Okanogan County |
| 2 | 99997 | zip | 98845; WA; Wenatchee; Douglas County; Palisades |
| 3 | 99996 | zip | 98844;WA;nan;Oroville;Okanogan County |
| 4 | 99995 | zip | 98843;WA;Wenatchee, WA;Orondo;Douglas County |
| ... | ... | ... | ... |
| 89300 | 100000 | zip | 98848;WA;Moses Lake, WA;Quincy;Grant County |
| 89301 | 10000 | city | Bloomington;MD;nan;Garrett County |
| 89302 | 1000 | county | Echols County;GA;Valdosta, GA |
| 89303 | 100 | county | Bibb County;AL;Birmingham-Hoover, AL |
| 89304 | 10 | state | Colorado |
89305 rows × 3 columns
What if we just want cities?
cities = regions[regions.region_type == 'city']
cities
| region_id | region_type | region | |
|---|---|---|---|
| None | |||
| 10 | 9999 | city | Carrsville;VA;Virginia Beach-Norfolk-Newport N... |
| 20 | 9998 | city | Birchleaf;VA;nan;Dickenson County |
| 56 | 9994 | city | Wright;KS;Dodge City, KS;Ford County |
| 124 | 9987 | city | Weston;CT;Bridgeport-Stamford-Norwalk, CT;Fair... |
| 168 | 9980 | city | South Wilmington; IL; Chicago-Naperville-Elgin... |
| ... | ... | ... | ... |
| 89203 | 10010 | city | Atwood;KS;nan;Rawlins County |
| 89224 | 10008 | city | Bound Brook;NJ;New York-Newark-Jersey City, NY... |
| 89254 | 10005 | city | Chanute;KS;nan;Neosho County |
| 89290 | 10001 | city | Blountsville;AL;Birmingham-Hoover, AL;Blount C... |
| 89301 | 10000 | city | Bloomington;MD;nan;Garrett County |
28104 rows × 3 columns
cities.info()
<class 'pandas.core.frame.DataFrame'>
Index: 28104 entries, 10 to 89301
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 region_id 28104 non-null object
1 region_type 28104 non-null object
2 region 28104 non-null object
dtypes: object(3)
memory usage: 878.2+ KB
I like to look and see what things are stored as, too. Remember, the object type is very generic.
There are 28,125 rows of cities! How about counties?
counties = regions[regions.region_type == 'county']
counties
| region_id | region_type | region | |
|---|---|---|---|
| None | |||
| 94 | 999 | county | Durham County;NC;Durham-Chapel Hill, NC |
| 169 | 998 | county | Duplin County;NC;nan |
| 246 | 997 | county | Dubois County;IN;Jasper, IN |
| 401 | 995 | county | Donley County;TX;nan |
| 589 | 993 | county | Dimmit County;TX;nan |
| ... | ... | ... | ... |
| 89069 | 1003 | county | Elmore County;AL;Montgomery, AL |
| 89120 | 1002 | county | Elbert County;GA;nan |
| 89204 | 1001 | county | Elbert County;CO;Denver-Aurora-Lakewood, CO |
| 89302 | 1000 | county | Echols County;GA;Valdosta, GA |
| 89303 | 100 | county | Bibb County;AL;Birmingham-Hoover, AL |
3097 rows × 3 columns
Can’t find the regions you want? You could export the whole thing to a CSV file and explore it in Excel. This will show up in whatever folder you currently have as your home in VS Code.
counties.to_csv('counties.csv', index = True)
You can also open up the Variables window in VS Code VS Code (or the equivalent in Google Colab) and scroll through the file, looking for the region_id values that you want.
Finally, you can search the text in a column directly. Let’s find counties in NC.
nc_counties = counties[counties['region'].str.contains(";NC")]
nc_counties
| region_id | region_type | region | |
|---|---|---|---|
| None | |||
| 94 | 999 | county | Durham County;NC;Durham-Chapel Hill, NC |
| 169 | 998 | county | Duplin County;NC;nan |
| 2683 | 962 | county | Craven County;NC;New Bern, NC |
| 4637 | 935 | county | Chowan County;NC;nan |
| 4972 | 93 | county | Ashe County;NC;nan |
| ... | ... | ... | ... |
| 87475 | 1180 | county | Martin County;NC;nan |
| 87821 | 1147 | county | Lenoir County;NC;Kinston, NC |
| 88578 | 1059 | county | Greene County;NC;nan |
| 88670 | 1049 | county | Graham County;NC;nan |
| 88823 | 1032 | county | Gaston County;NC;Charlotte-Concord-Gastonia, N... |
100 rows × 3 columns
nc_counties.info()
<class 'pandas.core.frame.DataFrame'>
Index: 100 entries, 94 to 88823
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 region_id 100 non-null object
1 region_type 100 non-null object
2 region 100 non-null object
dtypes: object(3)
memory usage: 3.1+ KB
There are 100 counties in NC, so this worked. Now, we can save these regions to a list and use that to pull data.
By exploring the data like this, you can maybe find the region_id values that you want and give them as a list. I’m also going to use the qopts = option to name the columns that I want to pull. This isn’t necessary here, since I want all of the columns, but I wanted to show you that you could do this.
nc_county_list = nc_counties['region_id'].to_list()
I’m going to pull down just the NC counties. I’ll comment out my code, though, so that I don’t download from the API every time I update my notes. This can cause a time-out error.
#zillow_nc = nasdaqdatalink.get_table('ZILLOW/DATA', indicator_id = 'ZATT', paginate = True, region_id = nc_county_list, qopts = {'columns': ['indicator_id', 'region_id', 'date', 'value']})
#zillow_nc.head(25)
Hey, there’s Durham County!
#zillow_nc.info()
Now you can filter by date if you like. And, you could pull down multiple states this way, change the variable type, etc. You could also merge in the region names using region_id as your key.
Using Rapid API#
Another data option is Rapid API. There’s all types of data here - markets, sports, gambling, housing, etc. People will write their own APIs, perhaps interfacing with the websites that contain the information. They can then publish their APIs on this webpage. Many have free options, some you have to pay for. There are thousands here, so you’ll have to dig around.
Fig. 38 Main Rapid API webpage#
One you have an account, you’ll be able to subscribe to different APIs. You probably want the data to have a free option.
The quick start guide is here.
Luckily, all of the APIs here tend to have the same structures. These are called REST APIs. This stands for “Representational State Transfer” and is just a standardized way for computers to talk to each other. They are going to use a standard data format, like JSON. More on this below.
You can read more on their API Learn page.
We’ll look at one example, Pinnacle Odds, which has some sports gambling information: https://rapidapi.com/tipsters/api/pinnacle-odds/
Once you’ve subscribed, you see the main endpoint screen.
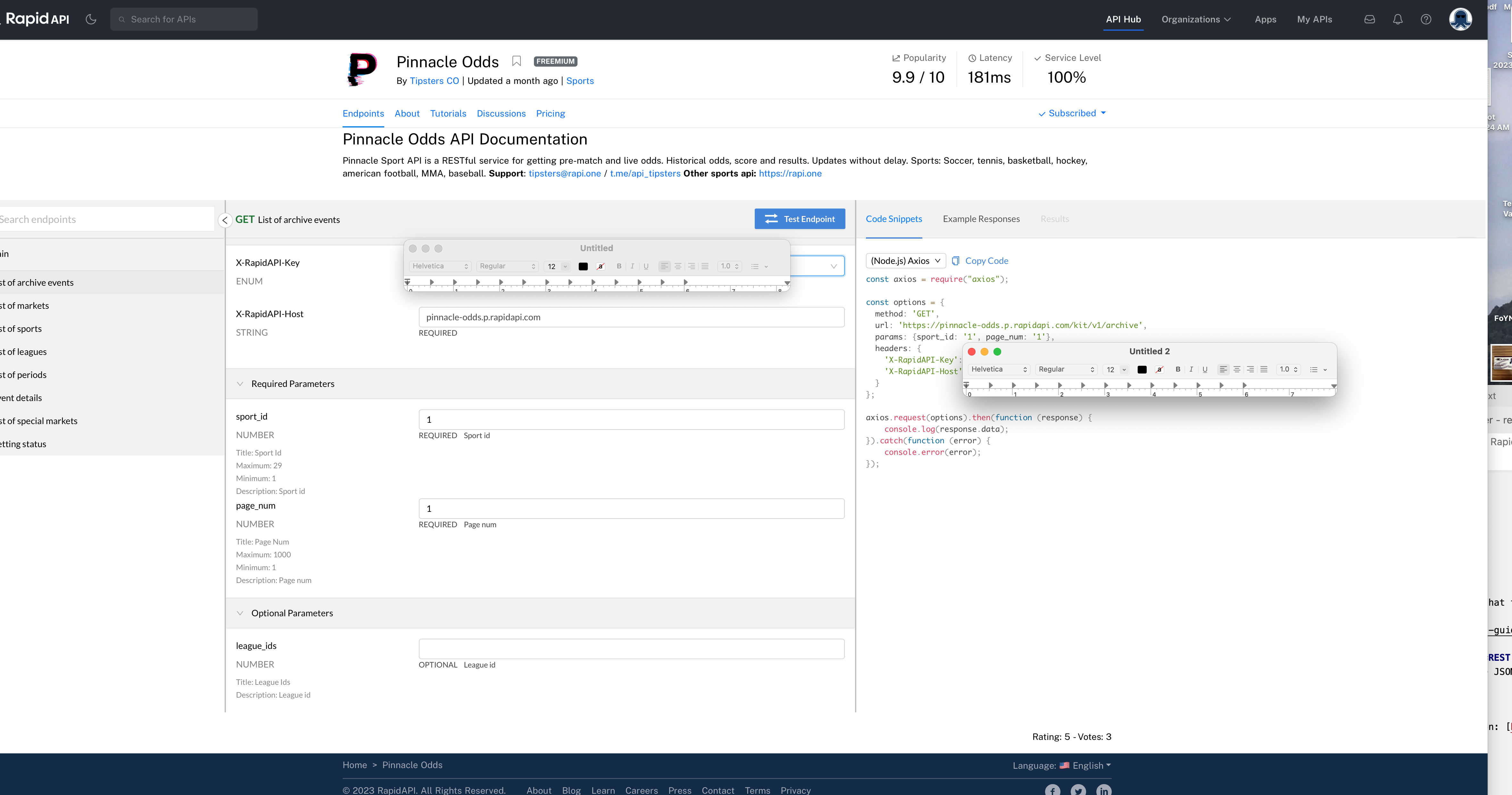
Fig. 39 Pinnacle Odds endpoint page. I’ve blocked my API key with two different windows.#
At the top, you’ll see Endpoints, About, Tutorials, Discussions, and Pricing. Click around to read more about the API.
We are currently on Endpoints. Endpoints are basically like URLs. They are where different tables of data live. We are going to use this page to figure out the data that we need. And, the webpage page will also create the Python code needed to download the data!
You can start on the left of the screen. You’ll see a list of the different tables available. I’ll try List of Sports in this example. You’ll see why in a minute.
You’ll note that the middle section now changed. This is where you can filter and ask for particular types of data from that table. In this case, there are no options to change.
On the right, you’ll see Code Snippets. The default is Node.js, a type of Javascript. We don’t want that. Click the dropdown box and look for Python. They have three ways, using three different packages, to interface with the API from Python and download the data. I’ll pick Requests - it seemed to work below.
This will change the code. You’ll see the package import, your API key, the host, and the data request. You can click Copy Code.
But, before we run this on our end, let’s click Test Endpoint. That’s the blue box in the middle. Then, click Results on the left and Body. By doing this, we essentially just ran that code in the browser. We can see what data we’re going to get. This is a JSON file with 9 items. Each item has 6 keys. You can see what the keys are - they are giving us the ids for each sport. For example, “Soccer” is “id = 1”.
This is very helpful! We need to know these id values if we want to pull particular sports.
For fun, let’s pull this simple JSON file on our end. I’ve copied and pasted the code below. It didn’t like the print function, so I just dropped it. I am again loading in my API key from an separate file. You’ll use your own.
I am commenting out my code so that it doesn’t run and use my API key everytime I update my book.
# import requests
# from dotenv import load_dotenv # For my .env file which contains my API keys locally
# import os # For my .env file which contains my API keys locally
# load_dotenv() # For my .env file which contains my API keys locally
# RAPID_API_KEY = os.getenv('RAPID_API_KEY')
# url = "https://pinnacle-odds.p.rapidapi.com/kit/v1/sports"
# headers = {
# "X-RapidAPI-Key": RAPID_API_KEY,
# "X-RapidAPI-Host": "pinnacle-odds.p.rapidapi.com"
# }
# sports_ids = requests.request("GET", url, headers=headers)
# print(sports_ids.text)
We can turn that response file into a JSON file. This is what it wants to be!
Again, all of the code that follows is also commented out so that it doesn’t run every time I edit this online book. The output from the code is still there, however.
#sports_ids_json = sports_ids.json()
#sports_ids_json
That’s JSON. I was able to show the whole thing in the notebook.
Let’s get that into a pandas DataFrame now. To do that, we have to know a bit about how JSON files are structured. This one is easy. pd.json_normalize is a useful tool here.
#sports_ids_df = pd.json_normalize(data = sports_ids_json)
#sports_ids_df
What do all of those columns mean? I don’t know! You’d want to read the documentation for your API.
Also, note how I’m changing the names of my objects as I go. I want to keep each data structure in memory - what I originally downloaded, the JSON file, the DataFrame. This way, I don’t overwrite anything and I won’t be forced to download the data all over again.
Now, let’s see if we can pull some actual data. I notice that id = 3 is Basketball. Cool. Let’s try for some NBA data. Go back to the left of the Endpoint page and click on List of archive events. The middle will change and you’ll have some required and optional inputs. I know I want sport_id to be 3. But I don’t want all basketball. Just the NBA. So, I notice the league_ids option below. But I don’t know the number of the NBA.
OK, back to the left side. See List of leagues? Click that. I put in sport_id = 3. I then click Test Endpoint. I go to Results, select Body, and then Expand All. I do a CTRL-F to look for “NBA”.
And I find a bunch of possibilities! NBA games. Summer League. D-League. Summer League! If you’re betting on NBA Summer League, please seek help. Let’s use the regular NBA. That’s league_id = 487.
Back to List of archive events. I’ll add that league ID to the bottom of the middle. I set the page_num to 1000. I then click Test Endpoint and look at what I get.
Nothing! That’s an empty looking file on the right. Maybe this API doesn’t keep archived NBA? Who knows.
Let’s try another endpoint. Click on List of markets. Let’s see what this one has. In the middle, I’ll again use the codes for basketball and the NBA. I’ll set is_have_odds to True. Let’s test the endpoint and see what we get.
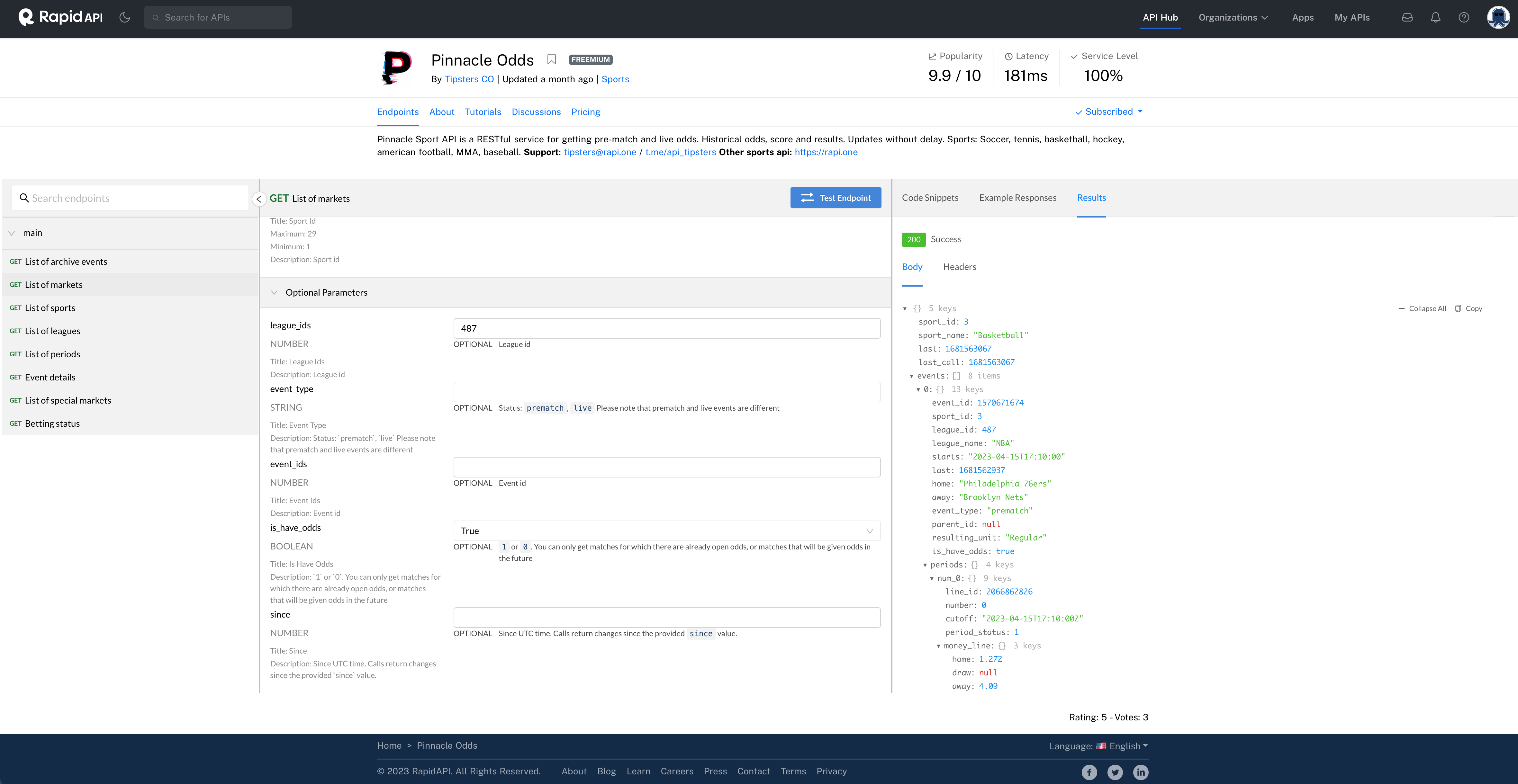
Fig. 40 Some NBA odds for this weekend.#
We can expand the result and look at the data structure. This is a more complicated one. I see 8 items under events. These correspond to the 8 games this weekend. Then, under each event, you can keep drilling down. The level 0 is kind of like the header for that event. It has the game, the start time, the teams, etc. You’ll see 4 more keys under periods. Each of these is a different betting line, with money lines, spreads, what I think are over/under point totals, etc.
Anyway, the main thing here is that we have indeed pulled some rather complex looking data. That data is current for upcoming games, not historical. But, we can still pull this in and use it to see how to work with a more complex JSON structure.
I’ll copy and paste the code again.
# import requests
# url = "https://pinnacle-odds.p.rapidapi.com/kit/v1/markets"
# querystring = {"sport_id":"3","league_ids":"487","is_have_odds":"true"}
# headers = {
# "X-RapidAPI-Key": RAPID_API_KEY,
# "X-RapidAPI-Host": "pinnacle-odds.p.rapidapi.com"
# }
# current = requests.request("GET", url, headers=headers, params=querystring)
# print(current.text)
Does that query string above make sense now?
I’ll convert that data to JSON below and peak at it.
#current_json = current.json()
#current_json
Wow, that’s a lot of stuff. OK, now this is the tricky part. How do we get this thing into a pandas DataFrame? This is where we really have to think carefully. What do we actually want? Remember, a DataFrame, at its simplest, looks like a spreadsheet, with rows and columns. How could this thing possibly look like that?
#current_df = pd.json_normalize(data = current_json)
#current_df
We need to flatten this file. JSON files are nested. That’s what all those brackets are doing. Let’s think a little more about that.
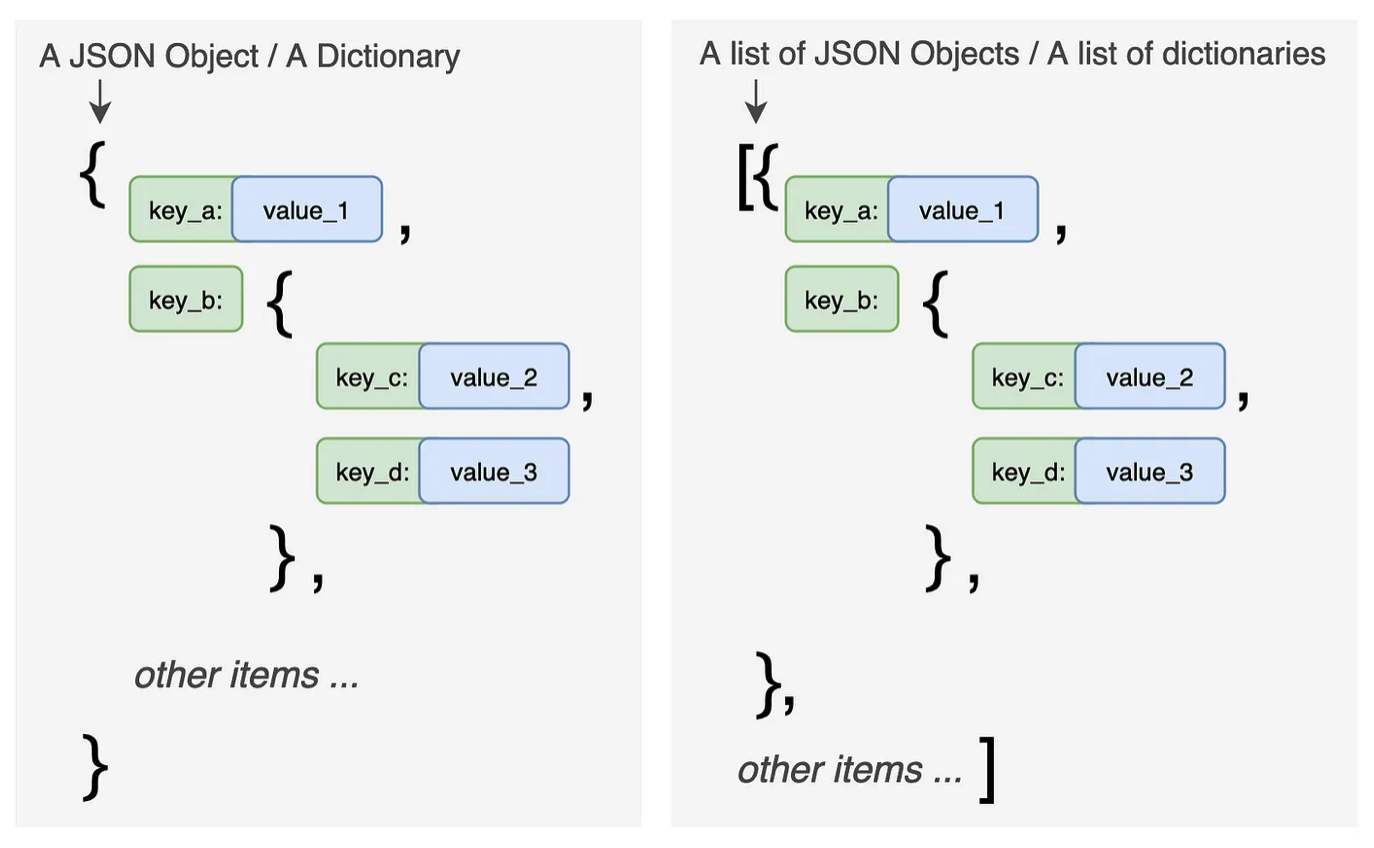
Fig. 41 JSON structure. Source: https://towardsdatascience.com/all-pandas-json-normalize-you-should-know-for-flattening-json-13eae1dfb7dd#
JSON files are like dictionaries, as you can see in the picture above. There’s a key and a value. However, they can get complicated where there’s a list of dictionaries embedded in the same data structure. You can think of navigating them like working through the branches of a tree. Which branch do you want?
To do this, we’ll use the pd.json_normalize method. We’ve just used it, but that was with a simple JSON file. It didn’t really work with the current odds data, unless we add more arguments.
You can read more here.
Everything is packed into that events column. Let’s flatten it. This will take every item in it and convert it into a new column. Keys will be combined together to create compound names that combine different levels.
#current_df_events = pd.json_normalize(data = current_json, record_path=['events'])
#current_df_events
#list(current_df_events)
That’s a lot of columns! Do you see what it did? When I flattened the file, it worked its way through the dictionary and key values. So, periods to num_0 to totals to the various over/under values, etc. It then combined those permutations to create new columns, where each value is separated by a period. Then value at the end of the chain is what goes into the DataFrame.
That’s a quick introduction to Rapid API and dealing with its JSON output. Every API is different - you’ll have to play around.
Data on Kaggle#
Kaggle is also a great source for data. You can search their data sets here.
Searching for finance, I see one on consumer finance complaints that looks interesting. The Kaggle page describes the data, gives you a data dictionary, and some examples.
The data for Kaggle contests is usually pretty clean already. That said, you’ll usually have to do at least some work to get it ready to look at.